 이 누리집은 대한민국 공식 전자정부 누리집입니다.
이 누리집은 대한민국 공식 전자정부 누리집입니다.
자료검색
본문검색 서비스
원문 PDF자료에 대한 책단위/페이지단위 내용 검색을 통해
보다 편리하게 온라인 자료의 콘텐츠를 이용할 수 있는
‘본문검색 서비스’
보다 편리하게 온라인 자료의 콘텐츠를 이용할 수 있는
‘본문검색 서비스’

서비스 소개
 서비스 소개
서비스 소개
본문검색 서비스는 국립중앙도서관이 소장하고 있는 디지털 원문 PDF 자료와 약 1만여건의 OCR PDF자료의 본문 내용을 책단위/페이지단위로
검색할 수 있는 서비스 입니다. 관내에서만 접속 및 이용이 가능하도록 운영되고 있습니다.
※ OCR PDF란?
이미지파일의 문자를 인식하여 텍스트 데이터로 치환하는 OCR(Optical Character Recognition) 광학 문자 인식기능을 사용하여 변환된 PDF
본문검색 서비스는 2011년부터 2015년까지의 일반도서 및 학술논문(학술지, 학위논문(석/박사)을 검색 대상으로 제공하고 있으며, 앞으로 계속해서 검색 대상 자료를 늘려 갈 예정입니다.
본문검색 프로세스
-
국립중앙도서관
원문자료수집 
-
원문자료 내
텍스트파일 추출 -
추출된 텍스트파일
형태소 분석 -
데이터 색인
-
본문검색
서비스제공
유의사항
- 검색 대상 자료에 OCR 광학 인식자료가 포함되어 있어 본문검색 서비스 운영 기간 중 검색결과가 다소 부정확할 수 있습니다.
- 본문검색 서비스는 국립중앙도서관 관내에서만 이용하실 수
있습니다.
본문 내용 검색
책 단위 내용 검색
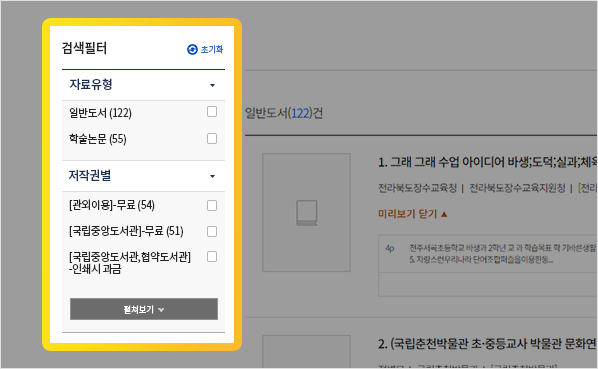
-문장 또는 키워드로 본문 내용을 검색하여 자료유형/저작권유형별로 검색된 자료 목록을 한눈에 확인할 수 있습니다.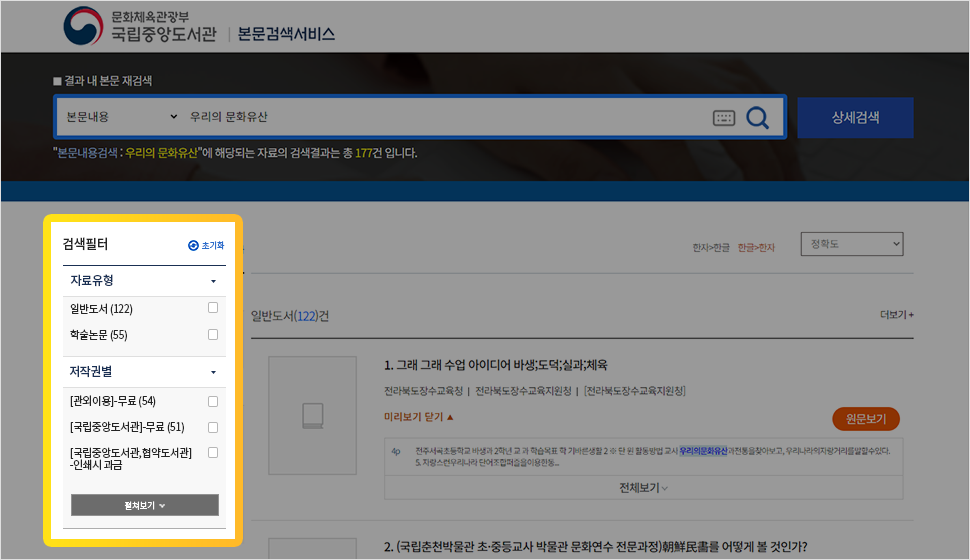
페이지 단위 내용 검색
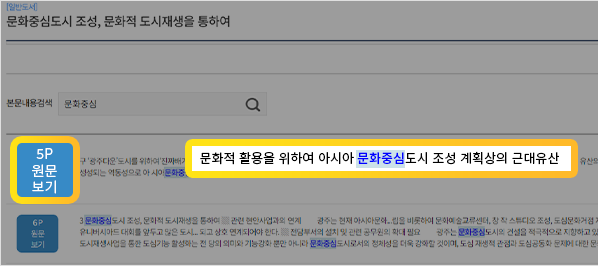
-자료의 상세화면에서 본문 내용을 검색하여, 페이지 정보 및 본문내용을 바로 확인할 수 있습니다.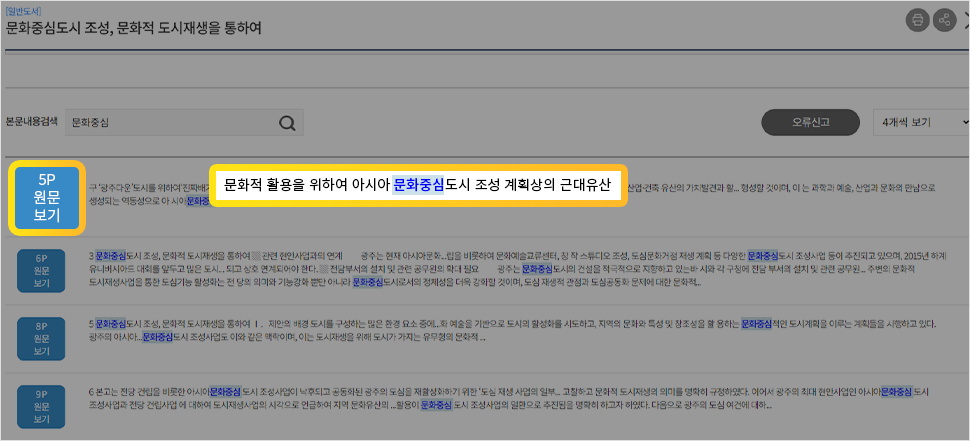
원문자료 통합뷰어 서비스
- 통합뷰어 서비스를 통해 검색한 원문 자료를 바로 이용할 수 있습니다.
검색 대상 자료 전체 키워드 분석 현황 제공
- 검색 대상 자료들의 전체 키워드를 분석 및 추출하여 분포 비율을 크기로 나타내어, 자료 유형별 전체 키워드 분석현황을 한눈에 살펴볼 수 있습니다.



